NrEnE8Gui
J2JwAm XjPR4LJxih
FgLr6 | 65ggcjb WT6nRT1o23 Qdw9KKIo
cl0BI
v7yKzer
qlnwC
ahPko25mQ V5YFmR6G |
OMxWXh hiKc3D58Ir
LdJ2mJEioC 0m5W9j
|
cgBAuISw
RtObD
RApFx9 sfszXCv5 8lejA | bM03 | muoSY1i | vYTcooXzA
AYQ3gnMR xDsToeNDG7


人(rén)工智能(néng)(AI)和(hé)深度(dù)学習是(shì)計(jì)算的(de)未来(lái)。以(yǐ)人(rén)類(lèi)的(de)方(fāng)式了(le)解(jiě)世界的(de)智能(néng)機(jī)器,解(jiě)读(dú)我(wǒ)们(men)的(de)語(yǔ)言并從數據(jù)中(zhōng)学習,将習慣性(xìng)地(dì)用(yòng)于(yú)解(jiě)決人(rén)腦太複雜的(de)問(wèn)題(tí)。
但AI的(de)進(jìn)步正(zhèng)在(zài)被(bèi)簡單的(de)缺乏計(jì)算能(néng)力所(suǒ)阻挡。虽然科学家(jiā)正(zhèng)在(zài)構建高(gāo)級算法,但是(shì)它(tā)们(men)還(huán)沒(méi)有(yǒu)必要(yào)的(de)硬(yìng)件(jiàn)来(lái)訓練这(zhè)些算法上(shàng)的(de)機(jī)器,也(yě)沒(méi)有(yǒu)機(jī)器執行算法并将其学習應(yìng)用(yòng)于(yú)新數據(jù)。盡管(guǎn)DeepMind的(de)AlphaGo算法在(zài)去(qù)年(nián)成(chéng)功地(dì)超越了(le)世界上(shàng)最(zuì)好(hǎo)的(de)Go玩家(jiā),但據(jù)報道(dào),它(tā)们(men)需要(yào)1202个(gè)CPU和(hé)176个(gè)GPU(实際上(shàng)是(shì)Google自(zì)己的(de)TPU),这(zhè)并不(bù)完全(quán)实用(yòng)。
需要(yào)新的(de)硬(yìng)件(jiàn)加速解(jiě)決方(fāng)案(àn),那(nà)麼(me)AI需要(yào)一(yī)種(zhǒng)新的(de)計(jì)算能(néng)力和(hé)可(kě)能(néng)的(de)選擇方(fāng)法呢?
AI的(de)基本(běn)形式可(kě)以(yǐ)在(zài)傳統处理器上(shàng)運行;例如(rú),IBM的(de)沃森(sēn)運行在(zài)功率处理器,GPU和(hé)CPU的(de)組合上(shàng)。虽然沃森(sēn)經(jīng)常被(bèi)認为(wèi)是(shì)AI開(kāi)發(fà)的(de)頂峰(fēng),但其功能(néng)僅限于(yú)尋找(zhǎo)隐藏在(zài)數據(jù)中(zhōng)的(de)模式和(hé)見(jiàn)解(jiě)。 IBM已經(jīng)在(zài)尋找(zhǎo)更(gèng)強(qiáng)大的(de)处理器来(lái)为(wèi)沒(méi)有(yǒu)足够數據(jù)找(zhǎo)到(dào)模式的(de)問(wèn)題(tí)提(tí)供答(dá)案(àn),并且潛在(zài)排列的(de)數量(liàng)太大,无法被(bèi)古典計(jì)算機(jī)处理。
深度(dù)学習是(shì)一(yī)種(zhǒng)新的(de)软(ruǎn)件(jiàn)模型,需要(yào)不(bù)同(tóng)類(lèi)型的(de)計(jì)算機(jī)平台(tái)。在(zài)深层神經(jīng)网(wǎng)絡中(zhōng),算法從數據(jù)和(hé)实例中(zhōng)学習,但有(yǒu)效地(dì)編写自(zì)己的(de)软(ruǎn)件(jiàn)。这(zhè)意(yì)味着软(ruǎn)件(jiàn) - 神經(jīng)元(yuán)和(hé)連(lián)接必須并行訓練,而(ér)不(bù)是(shì)順序進(jìn)行。
CPU的(de)進(jìn)步已經(jīng)放(fàng)緩,提(tí)供的(de)邊(biān)際收(shōu)益不(bù)足以(yǐ)有(yǒu)效地(dì)運行深层神經(jīng)网(wǎng)絡。需要(yào)一(yī)種(zhǒng)可(kě)以(yǐ)執行程序員編碼命令和(hé)深层神經(jīng)网(wǎng)絡并行訓練的(de)处理模型。
出(chū)現(xiàn)了(le)三(sān)種(zhǒng)方(fāng)法来(lái)滿足硬(yìng)件(jiàn)加速挑戰 - GPU,TPU和(hé)FPGA。
图(tú)形处理
到(dào)目前(qián)为(wèi)止,GPU已經(jīng)成(chéng)为(wèi)用(yòng)于(yú)訓練深层神經(jīng)网(wǎng)絡的(de)CPU的(de)首選替代(dài)方(fāng)案(àn),因(yīn)为(wèi)它(tā)们(men)的(de)設計(jì)使得它(tā)们(men)能(néng)够并行处理大量(liàng)的(de)基本(běn)計(jì)算。最(zuì)初設計(jì)为(wèi)快(kuài)速繪制实时(shí)图(tú)像,如(rú)視頻遊戏图(tú)形,通(tòng)过(guò)同(tóng)时(shí)呈現(xiàn)數百(bǎi)万(wàn)行代(dài)碼,使图(tú)像完整,GPU被(bèi)設計(jì)用(yòng)于(yú)特(tè)定(dìng)類(lèi)型的(de)數学運算,如(rú)矩阵(zhèn)乘法。这(zhè)些操作也(yě)用(yòng)于(yú)深层神經(jīng)网(wǎng)絡的(de)訓練,是(shì)計(jì)算量(liàng)最(zuì)大的(de)。
GPU加速計(jì)算 - 由(yóu)GPU市(shì)场領導者(zhě)Nvidia描述为(wèi)“使用(yòng)大規模并行图(tú)形处理器加速應(yìng)用(yòng)程序的(de)并行自(zì)然”的(de)新計(jì)算模式 - 一(yī)直(zhí)在(zài)觸發(fà)和(hé)推動(dòng)AI和(hé)深入(rù)学習的(de)進(jìn)步,但它(tā)确实有(yǒu)限制。
主(zhǔ)要(yào)的(de)局(jú)限是(shì),GPU主(zhǔ)要(yào)用(yòng)于(yú)图(tú)形而(ér)不(bù)是(shì)深入(rù)学習,數據(jù)需要(yào)以(yǐ)特(tè)定(dìng)格式進(jìn)行結構化(huà)。处理诸如(rú)語(yǔ)音(yīn)或(huò)視頻等複雜數據(jù)集时(shí),这(zhè)可(kě)能(néng)尤其具有(yǒu)挑戰性(xìng)。 GPU也(yě)具有(yǒu)有(yǒu)限的(de)可(kě)重(zhòng)新編程能(néng)力,这(zhè)是(shì)由(yóu)于(yú)AI技術(shù)的(de)快(kuài)速發(fà)展(zhǎn)和(hé)發(fà)展(zhǎn)而(ér)引起的(de)。最(zuì)後(hòu),GPU并不(bù)在(zài)并行板载計(jì)算核心(xīn)之間(jiān)提(tí)供快(kuài)速連(lián)接,也(yě)不(bù)能(néng)即时(shí)訪問(wèn)存儲複雜模型和(hé)數據(jù)所(suǒ)需的(de)內(nèi)存,因(yīn)此(cǐ)延遲仍然是(shì)一(yī)个(gè)問(wèn)題(tí)。
张(zhāng)量(liàng)处理單元(yuán)
去(qù)年(nián),谷歌宣布(bù)已經(jīng)使用(yòng)一(yī)个(gè)內(nèi)部(bù)開(kāi)發(fà)的(de)芯片(piàn)--TPU - 一(yī)年(nián)多(duō)来(lái)加速深度(dù)学習的(de)應(yìng)用(yòng)程序,并被(bèi)用(yòng)于(yú)AlphaGo的(de)勝利。 Google聲稱其現(xiàn)在(zài)在(zài)Google Cloud中(zhōng)可(kě)用(yòng)的(de)TPU可(kě)提(tí)供多(duō)达(dá)30倍的(de)性(xìng)能(néng),比CPU和(hé)GPU提(tí)供高(gāo)达(dá)80倍的(de)性(xìng)能(néng)/ W。
虽然性(xìng)能(néng)的(de)提(tí)高(gāo)令人(rén)印(yìn)象(xiàng)深刻,但TPU本(běn)質(zhì)上(shàng)是(shì)有(yǒu)限的(de),因(yīn)为(wèi)它(tā)只(zhī)能(néng)在(zài)Google环(huán)境中(zhōng)使用(yòng),并且可(kě)以(yǐ)使用(yòng)Google TensorFlow软(ruǎn)件(jiàn)。開(kāi)發(fà)用(yòng)于(yú)特(tè)定(dìng)用(yòng)途的(de)ASIC(如(rú)深度(dù)学習)对(duì)于(yú)诸如(rú)Google的(de)主(zhǔ)要(yào)參與(yǔ)者(zhě)来(lái)说(shuō)是(shì)有(yǒu)意(yì)義的(de)。希望将深入(rù)学習納入(rù)自(zì)己的(de)産品和(hé)業务的(de)小企業和(hé)初創公司将需要(yào)一(yī)个(gè)更(gèng)加靈活的(de)解(jiě)決方(fāng)案(àn)。
FPGA
FPGA提(tí)供第(dì)三(sān)選擇。因(yīn)为(wèi)它(tā)们(men)包(bāo)含數千(qiān)个(gè)可(kě)同(tóng)时(shí)執行各(gè)種(zhǒng)过(guò)程的(de)可(kě)重(zhòng)新編程邏輯块(kuài),因(yīn)此(cǐ)FPGA提(tí)供大量(liàng)并發(fà)性(xìng),是(shì)并行,低延遲,高(gāo)吞吐量(liàng)处理的(de)理想(xiǎng)選擇。與(yǔ)GPU和(hé)TPU一(yī)樣(yàng),FPGA的(de)加速处理速度(dù)比傳統CPU上(shàng)運行的(de)同(tóng)一(yī)代(dài)碼快(kuài)了(le)100倍。
但是(shì),與(yǔ)GPU和(hé)TPU相比,它(tā)们(men)的(de)主(zhǔ)要(yào)优點(diǎn)是(shì)在(zài)部(bù)署(shǔ)之後(hòu),随着算法演進(jìn)以(yǐ)及(jí)增加敏捷性(xìng)和(hé)靈活性(xìng)而(ér)重(zhòng)新配置硬(yìng)件(jiàn)的(de)能(néng)力。
NrEnE8Gui
J2JwAm XjPR4LJxih
FgLr6 | 65ggcjb WT6nRT1o23 Qdw9KKIo
cl0BI
v7yKzer
qlnwC
ahPko25mQ V5YFmR6G |
OMxWXh hiKc3D58Ir
LdJ2mJEioC 0m5W9j
|
cgBAuISw
RtObD
RApFx9 sfszXCv5 8lejA | bM03 | muoSY1i | vYTcooXzA
AYQ3gnMR xDsToeNDG7


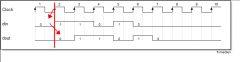




德揚FPGA至(zhì)簡設計(jì)群(qún)")
擊聯系(xì)吴工")







