






擊聯系(xì)吴工")

目前(qián),随着人(rén)工智能(néng)的(de)興起,GPU 借(jiè)助深度(dù)学習,走(zǒu)上(shàng)了(le)曆史的(de)舞(wǔ)台(tái),并且正(zhèng)如(rú)火如(rú)荼的(de)跑着各(gè)種(zhǒng)各(gè)樣(yàng)的(de)業务,從 training 到(dào) inference 都有(yǒu)它(tā)的(de)身(shēn)影。FPGA 也(yě)借(jiè)着这(zhè)股浪潮(cháo),慢(màn)慢(màn)地(dì)走(zǒu)向(xiàng)數據(jù)中(zhōng)心(xīn),發(fà)揮着它(tā)的(de)优勢。所(suǒ)以(yǐ)接下(xià)来(lái)就(jiù)講講 FPGA 如(rú)何能(néng)讓程序員们(men)更(gèng)好(hǎo)友好(hǎo)的(de)開(kāi)發(fà),而(ér)不(bù)需要(yào)写那(nà)些煩人(rén)的(de) RTL 代(dài)碼,不(bù)需要(yào)使用(yòng) VCS,Modelsim 这(zhè)樣(yàng)的(de)仿真(zhēn)软(ruǎn)件(jiàn),就(jiù)能(néng)輕(qīng)輕(qīng)松松实現(xiàn) unit test。
实現(xiàn)这(zhè)一(yī)編程思(sī)想(xiǎng)的(de)轉(zhuǎn)變(biàn),是(shì)因(yīn)为(wèi) FPGA 借(jiè)助 OpenCL 实現(xiàn)了(le)編程,程序員只(zhī)需要(yào)通(tòng)过(guò) C/C++ 添加适當的(de) pragma 就(jiù)能(néng)实現(xiàn) FPGA 編程。为(wèi)了(le)讓您用(yòng) OpenCL 实現(xiàn)的(de) FPGA 應(yìng)用(yòng)能(néng)够有(yǒu)更(gèng)高(gāo)的(de)性(xìng)能(néng),您需要(yào)熟悉如(rú)下(xià)介紹的(de)硬(yìng)件(jiàn)。另(lìng)外(wài),将会(huì)介紹編譯优化(huà)選項,有(yǒu)助于(yú)将您的(de) OpenCL 應(yìng)用(yòng)更(gèng)好(hǎo)的(de)实現(xiàn) RTL 的(de)轉(zhuǎn)換和(hé)映射,并部(bù)署(shǔ)到(dào) FPGA 上(shàng)執行。
FPGA 概覽
FPGA 是(shì)高(gāo)規格的(de)集成(chéng)電(diàn)路(lù),可(kě)以(yǐ)实現(xiàn)通(tòng)过(guò)不(bù)斷的(de)配置和(hé)拼接,达(dá)到(dào)无限精度(dù)的(de)函(hán)數功能(néng),因(yīn)为(wèi)它(tā)不(bù)像 CPU 或(huò)者(zhě) GPU 那(nà)樣(yàng),基本(běn)數據(jù)類(lèi)型的(de)位宽(kuān)都是(shì)固定(dìng)的(de),相反(fǎn) FPGA 能(néng)够做的(de)非(fēi)常靈活。在(zài)使用(yòng) FPGA 的(de)过(guò)程中(zhōng),特(tè)别适合一(yī)些 low-level 的(de)操作,比如(rú)像 bit masking、shifting、addition 这(zhè)樣(yàng)的(de)操作都可(kě)以(yǐ)非(fēi)常容易的(de)实現(xiàn)。
为(wèi)了(le)达(dá)到(dào)并行化(huà)計(jì)算,FPGA 內(nèi)部(bù)包(bāo)含了(le)查找(zhǎo)表(biǎo)(LUTs),寄存器(register),片(piàn)上(shàng)存儲(on-chip memory)以(yǐ)及(jí)算術(shù)運算硬(yìng)核(比如(rú)數字(zì)信(xìn)号(hào)处理器 (DSP) 块(kuài))。这(zhè)些 FPGA 內(nèi)部(bù)的(de)模块(kuài)通(tòng)过(guò)网(wǎng)絡連(lián)接在(zài)一(yī)起,通(tòng)过(guò)編程的(de)手(shǒu)段(duàn),可(kě)以(yǐ)对(duì)連(lián)接進(jìn)行配置,從而(ér)实現(xiàn)特(tè)定(dìng)的(de)邏輯功能(néng)。这(zhè)種(zhǒng)网(wǎng)絡連(lián)接可(kě)重(zhòng)配的(de)特(tè)性(xìng)为(wèi) FPGA 提(tí)供了(le)高(gāo)层次(cì)可(kě)編程的(de)能(néng)力。(FPGA 的(de)可(kě)編程性(xìng)就(jiù)體(tǐ)現(xiàn)在(zài)改變(biàn)各(gè)个(gè)模块(kuài)和(hé)邏輯資源之間(jiān)的(de)連(lián)接方(fāng)式)
舉个(gè)例子,查找(zhǎo)表(biǎo)(LUTs)體(tǐ)現(xiàn)的(de) FPGA 可(kě)編程能(néng)力,对(duì)于(yú)程序猿来(lái)说(shuō),可(kě)以(yǐ)等價理解(jiě)为(wèi)一(yī)个(gè)存儲器(RAM)。对(duì)于(yú) 3-bits 輸入(rù)的(de) LUT 可(kě)以(yǐ)等價理解(jiě)为(wèi)一(yī)个(gè)擁有(yǒu) 3 位地(dì)址線(xiàn)并且 8 个(gè) 1-bit 存儲單元(yuán)的(de)存儲器(一(yī)个(gè) 8 长度(dù)的(de)數組,數組內(nèi)每个(gè)元(yuán)素是(shì) 1bit)。那(nà)麼(me)當需要(yào)实現(xiàn) 3-bits 數字(zì)按位與(yǔ)操作的(de)时(shí)候,8 长度(dù)數組存的(de)是(shì) 3-bits 輸入(rù)數字(zì)的(de)按位與(yǔ)結果(guǒ),一(yī)共(gòng)是(shì) 8 種(zhǒng)可(kě)能(néng)性(xìng)。當需要(yào)实現(xiàn) 3-bits 按位异(yì)或(huò)的(de)时(shí)候,8 长度(dù)數組存的(de)是(shì) 3-bits 輸入(rù)數字(zì)的(de)按位异(yì)或(huò)結果(guǒ),一(yī)共(gòng)也(yě)是(shì) 8 種(zhǒng)可(kě)能(néng)性(xìng)。这(zhè)樣(yàng),在(zài)一(yī)个(gè)时(shí)鐘(zhōng)周期(qī)內(nèi),3-bits 的(de)按位運算就(jiù)能(néng)够獲取(qǔ)到(dào),并且实現(xiàn)不(bù)同(tóng)功能(néng)的(de)按位運算,完全(quán)是(shì)可(kě)編程的(de)(等價于(yú)修改 RAM 內(nèi)的(de)數值)。
3-bits 輸入(rù) LUT 实現(xiàn)按位與(yǔ)(bit-wise AND):
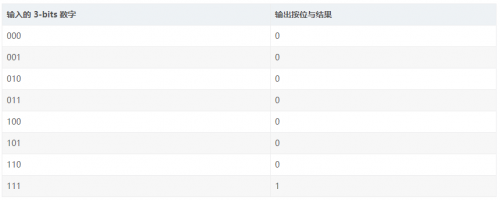
我(wǒ)们(men)看(kàn)到(dào)的(de)三(sān)輸入(rù)的(de)按位與(yǔ)操作,如(rú)下(xià)图(tú)所(suǒ)示,在(zài) FPGA 內(nèi)部(bù),可(kě)通(tòng)过(guò) LUT 实現(xiàn)。
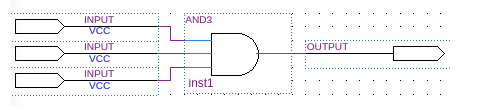
如(rú)上(shàng)展(zhǎn)示了(le) 3 輸入(rù),1 輸出(chū)的(de) LUT 实現(xiàn)。當将 LUT 并聯,串聯等方(fāng)式結合起来(lái)後(hòu)就(jiù)可(kě)以(yǐ)实現(xiàn)更(gèng)加複雜的(de)邏輯運算了(le)。
傳統 FPGA 開(kāi)發(fà)
▍傳統 FPGA 與(yǔ)软(ruǎn)件(jiàn)開(kāi)發(fà)对(duì)比
对(duì)于(yú)傳統的(de) FPGA 開(kāi)發(fà)與(yǔ)软(ruǎn)件(jiàn)開(kāi)發(fà),工具鍊(liàn)可(kě)以(yǐ)通(tòng)过(guò)下(xià)表(biǎo)簡單对(duì)比:
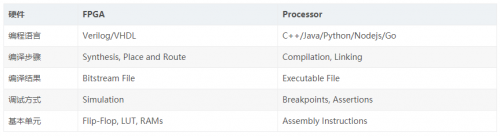
注:傳統 FPGA 與(yǔ)软(ruǎn)件(jiàn)開(kāi)發(fà)对(duì)比表(biǎo)
重(zhòng)點(diǎn)介紹一(yī)下(xià),編譯階(jiē)段(duàn)的(de) Synthesis (綜合),这(zhè)部(bù)分(fēn)與(yǔ)软(ruǎn)件(jiàn)開(kāi)發(fà)的(de)編譯有(yǒu)較大的(de)不(bù)同(tóng)。一(yī)般的(de)处理器 CPU、GPU 等,都是(shì)已經(jīng)生(shēng)産出(chū)来(lái)的(de) ASIC,有(yǒu)各(gè)自(zì)的(de)指令集可(kě)以(yǐ)使用(yòng)。但是(shì)对(duì)于(yú) FPGA,一(yī)切(qiè)都是(shì)空白,有(yǒu)的(de)只(zhī)是(shì)零(líng)部(bù)件(jiàn),什麼(me)都沒(méi)有(yǒu),但是(shì)可(kě)以(yǐ)自(zì)己創造任何結構形式的(de)電(diàn)路(lù),自(zì)由(yóu)度(dù)非(fēi)常的(de)高(gāo)。这(zhè)種(zhǒng)自(zì)由(yóu)度(dù)是(shì) FPGA 的(de)优勢,也(yě)是(shì)開(kāi)發(fà)过(guò)程中(zhōng)的(de)劣勢。
傳統 FPGA 開(kāi)發(fà)方(fāng)式
複雜系(xì)統,需要(yào)使用(yòng)有(yǒu)限狀态機(jī)(FSM),一(yī)般就(jiù)需要(yào)設計(jì)下(xià)图(tú)包(bāo)含的(de)三(sān)部(bù)分(fēn)邏輯:組合電(diàn)路(lù),时(shí)序電(diàn)路(lù),輸出(chū)邏輯。通(tòng)过(guò)組合邏輯獲取(qǔ)下(xià)一(yī)个(gè)狀态是(shì)什麼(me),时(shí)序邏輯用(yòng)于(yú)存儲當前(qián)狀态,輸出(chū)邏輯混合組合、时(shí)序電(diàn)路(lù),得到(dào)最(zuì)終(zhōng)輸出(chū)結果(guǒ)。
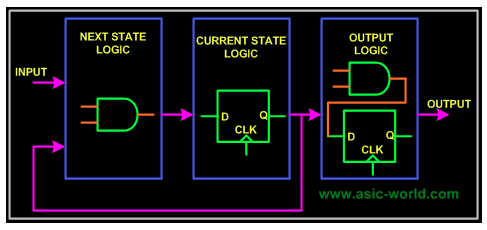
然後(hòu),針(zhēn)对(duì)具體(tǐ)算法,設計(jì)邏輯在(zài)狀态機(jī)中(zhōng)的(de)流轉(zhuǎn)过(guò)程:
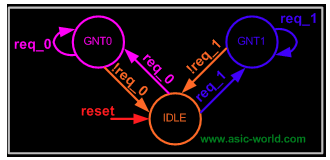
实現(xiàn)的(de) RTL 是(shì)这(zhè)樣(yàng)的(de):
module fsm_using_single_always (
clock , // clockreset , // Active high, syn resetreq_0 , // Request 0req_1 , // Request 1gnt_0 , // Grant 0gnt_1
);//=============Input Ports=============================input clock,reset,req_0,req_1; //=============Output Ports===========================output gnt_0,gnt_1;//=============Input ports Data Type===================wire clock,reset,req_0,req_1;//=============Output Ports Data Type==================reg gnt_0,gnt_1;//=============Internal Constants======================parameter SIZE = 3 ;
parameter IDLE = 3'b001,GNT0 = 3'b010,GNT1 = 3'b100 ;//=============Internal Variables======================reg [SIZE-1:0] state ;// Seq part of the FSMreg [SIZE-1:0] next_state ;// combo part of FSM//==========Code startes Here==========================always @ (posedge clock)begin : FSMif (reset == 1'b1) begin
state <= #1 IDLE;
gnt_0 <= 0;
gnt_1 <= 0;end else
case(state)
IDLE : if (req_0 == 1'b1) begin
state <= #1 GNT0;
gnt_0 <= 1; end else if (req_1 == 1'b1) begin
gnt_1 <= 1;
state <= #1 GNT1; end else begin
state <= #1 IDLE; end
GNT0 : if (req_0 == 1'b1) begin
state <= #1 GNT0; end else begin
gnt_0 <= 0;
state <= #1 IDLE; end
GNT1 : if (req_1 == 1'b1) begin
state <= #1 GNT1; end else begin
gnt_1 <= 0;
state <= #1 IDLE; end
default : state <= #1 IDLE;
endcaseendendmodule // End of Module arbiter
傳統的(de) RTL 設計(jì),对(duì)于(yú)程序員簡直(zhí)就(jiù)是(shì)噩夢啊,夢啊,啊~~~工具鍊(liàn)完全(quán)不(bù)同(tóng),開(kāi)發(fà)思(sī)路(lù)完全(quán)不(bù)同(tóng),還(huán)要(yào)分(fēn)析时(shí)序,一(yī)个(gè) Clock 节(jié)拍不(bù)对(duì),就(jiù)要(yào)推翻重(zhòng)来(lái),重(zhòng)新验(yàn)證,一(yī)切(qiè)都顯得太底层,不(bù)是(shì)很方(fāng)便。那(nà)麼(me),这(zhè)些就(jiù)交給(gěi)專業的(de) FPGAer 吧,下(xià)面(miàn)介紹的(de) OpenCL 開(kāi)發(fà) FPGA,有(yǒu)點(diǎn)像 25 歲的(de) Linux 了(le)。有(yǒu)了(le)高(gāo)层次(cì)的(de)抽象(xiàng)。用(yòng)起来(lái)自(zì)然也(yě)会(huì)更(gèng)加方(fāng)便。
▍基于(yú) OpenCL 的(de) FPGA 開(kāi)發(fà)
OpenCL 对(duì)于(yú) FPGA 開(kāi)發(fà),注入(rù)了(le)新鮮的(de)血(xuè)液,一(yī)種(zhǒng)面(miàn)向(xiàng)异(yì)構系(xì)統的(de)編程語(yǔ)言,将 FPGA 最(zuì)为(wèi)异(yì)構实現(xiàn)的(de)一(yī)種(zhǒng)可(kě)選設備。由(yóu) CPU Host 端控制整个(gè)程序的(de)執行流程,FPGA Device 端則作为(wèi)异(yì)構加速的(de)一(yī)種(zhǒng)方(fāng)式。异(yì)構架構,有(yǒu)助于(yú)解(jiě)放(fàng) CPU,将 CPU 不(bù)擅长的(de)处理方(fāng)式,下(xià)發(fà)到(dào) Device 端处理。目前(qián)典型的(de)异(yì)構 Device 有(yǒu):GPU、Intel Phi、FPGA。
OpenCL 是(shì)一(yī)个(gè)用(yòng)于(yú)异(yì)構平台(tái)編程的(de)框架,主(zhǔ)要(yào)的(de)异(yì)構設備有(yǒu) CPU、GPU、DSP、FPGA 以(yǐ)及(jí)一(yī)些其它(tā)的(de)硬(yìng)件(jiàn)加速器。OpenCL 基于(yú) C99 来(lái)開(kāi)發(fà)設備端代(dài)碼,并且提(tí)供了(le)相應(yìng)的(de) API 可(kě)以(yǐ)調用(yòng)。OpenCL 提(tí)供了(le)标(biāo)準的(de)并行計(jì)算的(de)接口(kǒu),以(yǐ)支持(chí)任务并行和(hé)數據(jù)并行的(de)計(jì)算方(fāng)式。
OpenCL 案(àn)例分(fēn)析
这(zhè)里(lǐ)采用(yòng) Altera 官网(wǎng)的(de)矩阵(zhèn)乘法案(àn)例進(jìn)行分(fēn)析。可(kě)以(yǐ)通(tòng)过(guò)如(rú)下(xià)鍊(liàn)接下(xià)载案(àn)例:Altera OpenCL Matrix Multiplication
代(dài)碼結構如(rú)下(xià):
.|-- common| |-- inc| | `-- AOCLUtils| | |-- aocl_utils.h| | |-- opencl.h| | |-- options.h| | `-- scoped_ptrs.h| |-- readme.css| `-- src| `-- AOCLUtils| |-- opencl.cpp| `-- options.cpp`-- matrix_mult
|-- Makefile
|-- README.html
|-- device
| `-- matrix_mult.cl
`-- host
|-- inc
| `-- matrixMult.h
`-- src
`-- main.cpp
其中(zhōng),和(hé) FPGA 相關(guān)的(de)代(dài)碼是(shì) matrix_mult.cl ,該部(bù)分(fēn)代(dài)碼描述了(le) kernel 函(hán)數,这(zhè)部(bù)分(fēn)函(hán)數会(huì)通(tòng)过(guò)編譯器生(shēng)成(chéng) RTL 代(dài)碼,然後(hòu) map 到(dào) FPGA 電(diàn)路(lù)中(zhōng)。
kernel 函(hán)數的(de)定(dìng)義如(rú)下(xià):
__kernel
__attribute((reqd_work_group_size(BLOCK_SIZE,BLOCK_SIZE,1)))
__attribute((num_simd_work_items(SIMD_WORK_ITEMS)))void matrixMult( __global float *restrict C,
__global float *A,
__global float *B,
int A_width,
int B_width)
模式比較固定(dìng),需要(yào)注意(yì)的(de)是(shì) __global 指明(míng)從 CPU 傳过(guò)来(lái)的(de)數據(jù),存放(fàng)到(dào)全(quán)局(jú)內(nèi)存中(zhōng),可(kě)以(yǐ)是(shì) FPGA 片(piàn)上(shàng)存儲資源,DDR,QDR 等,这(zhè)个(gè)視 FPGA 的(de) OpenCL BSP 驅動(dòng),会(huì)有(yǒu)所(suǒ)區(qū)别。num_simd_work_items 用(yòng)于(yú)指明(míng) SIMD 的(de)宽(kuān)度(dù)。reqd_work_group_size 指明(míng)了(le)工作組的(de)大小。这(zhè)些概念,可(kě)以(yǐ)參考 OpenCL 的(de)使用(yòng)手(shǒu)册。
函(hán)數实現(xiàn)如(rú)下(xià):
// 聲明(míng)本(běn)地(dì)存儲,暫存數組的(de)某一(yī)个(gè) BLOCK__local float A_local[BLOCK_SIZE][BLOCK_SIZE];
__local float B_local[BLOCK_SIZE][BLOCK_SIZE];// Block indexint block_x = get_group_id(0);int block_y = get_group_id(1);// Local ID index (offset within a block)int local_x = get_local_id(0);int local_y = get_local_id(1);// Compute loop boundsint a_start = A_width * BLOCK_SIZE * block_y;int a_end = a_start + A_width - 1;int b_start = BLOCK_SIZE * block_x;float running_sum = 0.0f;for (int a = a_start, b = b_start; a <= a_end; a += BLOCK_SIZE, b += (BLOCK_SIZE * B_width))
{ // 從 global memory 读(dú)取(qǔ)相應(yìng) BLOCK 數據(jù)到(dào) local memory
A_local[local_y][local_x] = A[a + A_width * local_y + local_x];
B_local[local_x][local_y] = B[b + B_width * local_y + local_x]; // Wait for the entire block to be loaded.
barrier(CLK_LOCAL_MEM_FENCE); // 計(jì)算部(bù)分(fēn),将計(jì)算單元(yuán)并行展(zhǎn)開(kāi),形成(chéng)乘法加法樹(shù)
#pragma unroll
for (int k = 0; k < BLOCK_SIZE; ++k)
{
running_sum += A_local[local_y][k] * B_local[local_x][k];
} // Wait for the block to be fully consumed before loading the next block.
barrier(CLK_LOCAL_MEM_FENCE);
}// Store result in matrix CC[get_global_id(1) * get_global_size(0) + get_global_id(0)] = running_sum;
采用(yòng) CPU 模拟仿真(zhēn) FPGA
对(duì)其進(jìn)行仿真(zhēn),不(bù)需要(yào) programer 關(guān)心(xīn)具體(tǐ)的(de)时(shí)序是(shì)怎麼(me)走(zǒu)的(de),只(zhī)需要(yào)验(yàn)證邏輯功能(néng)就(jiù)可(kě)以(yǐ),Altera OpenCL SDK 提(tí)供了(le) CPU 仿真(zhēn) Device 設備的(de)功能(néng),采用(yòng)如(rú)下(xià)方(fāng)式進(jìn)行:
# To generate a .aocx file for debugging that targets a specific accelerator board$ aoc -march=emulator device/matrix_mult.cl -o bin/matrix_mult.aocx --fp-relaxed --fpc --no-interleaving default --board <your-board># Generate Host exe.$ make# To run the application$ env CL_CONTEXT_EMULATOR_DEVICE_ALTERA=8 ./bin/host -ah=512 -aw=512 -bw=512
上(shàng)述脚本(běn)中(zhōng),通(tòng)过(guò) -march=emulator 設置創建一(yī)个(gè)可(kě)用(yòng)于(yú) CPU debug 的(de)設備可(kě)執行文(wén)件(jiàn)。-g 添加調試 flag。—board 用(yòng)于(yú)創建适配該設備的(de) debugging 文(wén)件(jiàn)。CL_CONTEXT_EMULATOR_DEVICE_ALTERA 为(wèi)用(yòng)于(yú) CPU 仿真(zhēn)的(de)設備數量(liàng)。
當執行上(shàng)述脚本(běn)後(hòu),輸出(chū)如(rú)下(xià):
$ env CL_CONTEXT_EMULATOR_DEVICE_ALTERA=8 ./bin/host -ah=512 -aw=512 -bw=512Matrix sizes:
A: 512 x 512
B: 512 x 512
C: 512 x 512Initializing OpenCL
Platform: Altera SDK for OpenCL
Using 8 device(s)
EmulatorDevice : Emulated Device
...
EmulatorDevice : Emulated Device
Using AOCX: matrix_mult.aocx
Generating input matrices
Launching for device 0 (global size: 512, 64)
...
Launching for device 7 (global size: 512, 64)
Time: 5596.620 ms
Kernel time (device 0): 5500.896 ms
...
Kernel time (device 7): 5137.931 ms
Throughput: 0.05 GFLOPS
Computing reference output
Verifying
Verification: PASS
通(tòng)过(guò)仿真(zhēn)时(shí)候設置 Device = 8,模拟 8 个(gè)設備運行 (512, 512) * (512, 512) 規模的(de)矩阵(zhèn),最(zuì)終(zhōng)验(yàn)證正(zhèng)确。接下(xià)来(lái)就(jiù)可(kě)以(yǐ)将其真(zhēn)正(zhèng)編譯到(dào) FPGA 設備上(shàng)後(hòu)運行。
FPGA 設備上(shàng)運行矩阵(zhèn)乘
这(zhè)个(gè)时(shí)候,真(zhēn)正(zhèng)要(yào)将代(dài)碼下(xià)载到(dào) FPGA 上(shàng)執行了(le),这(zhè)时(shí)候,只(zhī)需要(yào)做一(yī)件(jiàn)事(shì),那(nà)就(jiù)是(shì)用(yòng) OpenCL SDK 提(tí)供的(de)編譯器,将 *.cl 代(dài)碼适配到(dào) FPGA 上(shàng),執行編譯命令如(rú)下(xià):
$ aoc device/matrix_mult.cl -o bin/matrix_mult.aocx --fp-relaxed --fpc --no-interleaving default --board <your-board>
这(zhè)个(gè)过(guò)程比較慢(màn),一(yī)般需要(yào)幾(jǐ)个(gè)小时(shí)到(dào) 10 幾(jǐ)个(gè)小时(shí),視 FPGA 上(shàng)資源大小而(ér)定(dìng)。(目前(qián)这(zhè)部(bù)分(fēn)时(shí)間(jiān)太长暫时(shí)无法解(jiě)決,因(yīn)为(wèi)这(zhè)里(lǐ)的(de)編譯,其实是(shì)在(zài)行程一(yī)个(gè)能(néng)够正(zhèng)常工作的(de)電(diàn)路(lù),软(ruǎn)件(jiàn)会(huì)進(jìn)行布(bù)局(jú)布(bù)線(xiàn)等工作)
等待編譯完成(chéng)後(hòu),将生(shēng)成(chéng)的(de) matrix_mult.aocx 文(wén)件(jiàn)燒写到(dào) FPGA 上(shàng)就(jiù) ok 啦。
燒写的(de)命令如(rú)下(xià):
$ aocl program <your-board> matrix_mult.aocx
这(zhè)时(shí)候,大功告成(chéng),可(kě)以(yǐ)運行 host 端程序了(le):
$ ./host -ah=512 -aw=512 -bw=512Matrix sizes:
A: 512 x 512
B: 512 x 512
C: 512 x 512Initializing OpenCL
Platform: Altera SDK for OpenCL
Using 1 device(s)
<your-board> : Altera OpenCL QPI FPGA
Using AOCX: matrix_mult.aocx
Generating input matrices
Launching for device 0 (global size: 512, 512)
Time: 2.253 ms
Kernel time (device 0): 2.191 ms
Throughput: 119.13 GFLOPS
Computing reference output
Verifying
Verification: PASS
可(kě)以(yǐ)看(kàn)到(dào),矩阵(zhèn)乘法能(néng)够在(zài) FPGA 上(shàng)正(zhèng)常運行,吞吐大概在(zài) 119GFlops 左(zuǒ)右(yòu)。
小結
從上(shàng)述的(de)開(kāi)發(fà)流程,OpenCL 大大的(de)解(jiě)放(fàng)了(le) FPGAer 的(de)開(kāi)發(fà)周期(qī),并且对(duì)于(yú)软(ruǎn)件(jiàn)開(kāi)發(fà)者(zhě),也(yě)比較容易上(shàng)手(shǒu)。这(zhè)是(shì)他(tā)的(de)优勢,但是(shì)目前(qián)開(kāi)發(fà)过(guò)程中(zhōng),還(huán)是(shì)存在(zài)一(yī)些問(wèn)題(tí),如(rú):編譯器优化(huà)不(bù)足,相比 RTL 写的(de)性(xìng)能(néng)存在(zài)差距;編譯到(dào) Device 端时(shí)間(jiān)太长。不(bù)过(guò)这(zhè)些随着行業的(de)發(fà)展(zhǎn),一(yī)定(dìng)会(huì)慢(màn)慢(màn)的(de)進(jìn)步。
另(lìng)外(wài),对(duì) FPGA 感(gǎn)興趣,或(huò)者(zhě)有(yǒu)用(yòng) FPGA 做方(fāng)案(àn)的(de)同(tóng)学,欢迎一(yī)起探讨。
http://old.mdy-edu.com/xmucjie/2023/0201/1865.html

掃碼了(le)解(jiě)☝項目合作
德揚FPGA至(zhì)簡設計(jì)群(qún)")



